
각종 데이터 분석 실기시험 대비에 도움이 되는 파이썬 문법을 모아보았다. 그 첫 번째로 기본 문법을 다룬다.
객체 생성
기본 객체
리스트(list): 가장 기본이 되는 파이썬의 자료형. 향후 NumPy 또는 Pandas의 객체를 만들 때 활용되기도 한다.
1
2[1, 2, 3]
## [1, 2, 3]튜플(tuple): 수정이 불가하다. 보통 객체의 크기를 나타낼 때 주로 사용된다.
※ 원소가 1개인 튜플 생성시 쉼표 잊지 말것.1
2(1, 2, 3)
## (1, 2, 3)딕셔너리(dictionary): 키(key)와 값(value)의 쌍으로 이루어져 있다. 향후 Pandas의 DataFrame 객체를 만들 때 활용되기도 한다.
1
2{"A": [1, 2, 3], "B": ["a", "b"]}
## {"A": [1, 2, 3], "B": ["a", "b"]}range(): 0부터 시작하는 수열을 생성하며 반복문 등에 활용
1
2range(5)
## range(0, 5)
NumPy
- 어레이(array): 기본 행렬 연산을 지원
1
2
3
4
5
6np.array([1, 2, 3])
## array([1, 2, 3])
np.array([[1, 2], [3, 4]])
## array([[1, 2],
## [3, 4]])
np.arange(): 수열 생성(시작, 끝, 증분 지정가능)
1
2
3
4
5
6
7
8np.arange(4)
## array([0, 1, 2, 3])
np.arange(3, 6)
## array([3, 4, 5])
np.arange(5, 10, 2)
## array([5, 7, 9])np.r_[]: 이산, 연속 수열 생성 가능
1
2np.r_[1, 2, 5:9]
## array([1, 2, 5, 6, 7, 8])
Pandas
시리즈(Series): Pandas의 기본 객체이며 1차원
1
2
3
4
5pd.Series([1, 2, 3])
## 0 1
## 1 2
## 2 3
## dtype: int64데이터프레임(DataFrame): 원소의 개수가 같은 시리즈를 묶은 2차원 객채
※ 단, 각 변수에 할당되는 객체의 원소의 개수는 같아야 한다.1
pd.DataFrame({"A": [1, 2], "B": ["a", "b"]})
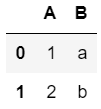
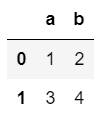
1 | pd.DataFrame(data = [[1, 2], [3, 4]], columns = ["a", "b"]) |
데이터 읽어오기
Pandas
csv: 자료가 쉼표로 구분되어있는 파일
1
df = pd.read_csv("file.csv")
txt: 일반 텍스트 파일. 특정 구분자로 구분되어있다면
sep인자에 명시해준다.1
df = pd.read_csv("file.csv", sep = "#")
tsv: 값이 탭(tab)으로 구분되어있는 텍스트 파일. 함수는
pd.read_csv()를 사용하며sep인자에 \t 를 입력해준다.1
df = pd.read_csv("file.csv", sep = "\t")
xlsx: 엑셀 파일. 특정 시트(sheet)의 데이터만 읽어올 경우
sheet_name인자에 시트명 또는 순번을 입력해준다.1
2
3df = pd.read_excel("file.xlsx")
df = pd.read_excel("file.xlsx", sheet_name = 0)
df = pd.read_excel("file.xlsx", sheet_name = "first_sheet")
객체 알아보기
기본 객체
함수 및 메서드
set(): 집합 관련 함수이나, 집합의 성질 때문에 중복 원소를 제거해줌1
2set([1, 1, 2, 3, 3])
## {1, 2, 3}len(): 객체의 원소 개수를 반환1
2len([3, 5, 7, 8])
## 4type(): 객체의 특징 확인1
2type([1, 2, 3])
## list
Numpy - array
함수 및 메서드
- .min(): 최소값
- .max(): 최대값
- .mean(): 평균값
- .argmax(): 최대값의 위치
- .argmin(): 최소값의 위치
1 | arr = np.array([[1, 2, 3], [10, 9, 8]]) |
속성(attribute)
- .ndim: 객체의 차원
- .shape: 각 차원의 길이
- .dtype: 데이터 타입
1 | arr = np.array([[1, 2, 3], [4, 5, 6]]) |
Pandas - Series
함수 및 메서드
- .min(): 최소값
- .max(): 최대값
- .mean(): 평균값
- .var(): 분산
- .std(): 표준편차
- .skew(): 왜도
- .kurt(): 첨도
- .idxmin(): 최소값의 위치(index)
- .idxmax(): 최대값의 위치(index)
1 | ser = pd.Series([1, 3, 5, 8, 4]) |
속성(attribute)
- .ndim: 객체의 차원
- .shape: 각 차원의 길이
- .dtype: 데이터 타입
1 | ser.ndim |
Pandas - DataFrame
함수 및 메서드
기본적으로 데이터프레임을 확인하는 메서드는 다음과 같다.
- .head(): 첫 5개 row 를 출력하며, 숫자 지정으로 개수를 조정할 수 있다.
- .tail(): 마지막 5개 row 를 출력하며, 숫자 지정으로 개수를 조정할 수 있다.
- len(): 기본 함수이지만 데이터 프레임에 사용하였을 때는 row 개수를 반환한다.
시리즈에서 사용했던 산술 연산 관련 메서드는 기본적으로 column 방향(axis = 0)으로 연산한 결과를 반환한다. row 방향으로 연산한 결과를 반환하려면 함수의 axis 인자에 1을 대입하면 된다.
- .min(): 최소값
- .max(): 최대값
- .mean(): 평균값
- .var(): 분산
- .std(): 표준편차
- .skew(): 왜도
- .kurt(): 첨도
- .idxmin(): 최소값의 위치(index)
- .idxmax(): 최대값의 위치(index)
1 | df = pd.DataFrame(data = [[1, 2], [3, 4]], columns = ["a", "b"]) |
속성(attribute)
- .ndim: 객체의 차원
- .shape: 각 차원의 길이
- .dtypes: 각 변수별 데이터 타입
1 | df = pd.DataFrame(data = [[1, 2], [3, 4]], columns = ["a", "b"]) |
사용자 정의 함수
define 을 뜻하는 def로 시작하며, 출력물은 꼭 return 뒤에 명시해주어야 한다.
1 | def udf(x): |
<실기시험 대비 시리즈 - Python>
Python 실기시험 대비 정리 노트 - 00
Python 실기시험 대비 정리 노트 - 01
Python 실기시험 대비 정리 노트 - 02
Python 실기시험 대비 정리 노트 - 03
Python 실기시험 대비 정리 노트 - 04

