
각종 데이터 분석 실기시험 대비에 도움이 되는 파이썬 문법을 모아보았다. 그 두 번째로 데이터 전처리를 다룬다.
기본 문법
연산자
- **: 지수 연산. 지수에 0.5을 입력할 경우 제곱근(root)으로 연산되어 np.sqrt() 대체 가능
- //: 나눗셈의 몫. 연령대 같은 경우 다섯살, 열살 단위로 나눌 때 유용하게 사용할 수 있다.
- %: 나눗셈의 나머지. 홀수와 짝수를 판별할 때 유용하게 사용할 수 있다.
- +: 문자열의 경우 이어붙일 수 있다. 단, 숫자는 문자로 변환 후 사용해야 한다.
- -: 리스트의 경우 -1은 마지막 원소, 데이터프레임 변수의 경우 마지막을 선택할 수 있다.
1 | ser = pd.Series([20, 42, 39, 16]) |
추가로 덧셈과 곱셈의 항등원 성질을 활용한 단일 가변수(dummy variable)를 만들기 위해서 + 또는 *를 사용하기도 한다.
1 | ser = pd.Series([20, 42, 39, 16]) |
기본 함수
리스트에 사용되는 산술함수는 Pandas Series에도 먹히나, Pandas 객체가 제공하는 메서드를 사용하면 되기 때문에 그다지 효용성이 없다.
- max(): 최대값
- min(): 최소값
- sum(): 합
- pow(): 지수 연산
자료형 변환을 위해 str(), int() 등 함수를 사용할 수 있으나, 되도록이면 Pandas Series의 .astype() 메서드 사용을 권장한다.
NumPy
특수하게 행렬을 다루는 극악 난이도의 전처리가 나오지 않는 이상 배열(array) 관련 함수는 거의 쓸 일이 없다. 그리고 대부분의 실기시험은 Pandas 데이터프레임 기반의 전처리가 주요하기 때문에 숙지해야할 함수가 몇 개 없다.
- .reshape(): 배열의 구조를 조정한다. 보통 2차원 배열에 사용하며 앞에는 row, 뒤에는 column의 길이를 명시한다.
- np.arange(): 기본함수 range()의 상위호환 함수이며 시작/끝/증분 세 종류를 설정할 수 있다.
- np.where(): 엑셀의 if() 함수, R의 ifelse() 함수와 동일한 기능을 한다.
- np.r_[]: 이산, 연속 수열을 한 번에 생성할 수 있으며, 특이하게 일반 함수처럼 소괄호가 아닌 대괄호를 사용한다. Pandas 데이터프레임의 다중 변수 선택에 활용할 수 있다.
1 | arr = np.arange(6).reshape(2, 3) |
Pandas
인덱스
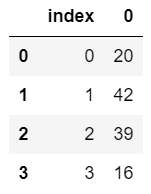
Series객체의 경우 .index로 접근 가능하나, 정확하게 값을 추출하려면 .values 또한 연쇄적으로 작성하여야 한다.
1 | ser = pd.Series([20, 42, 39, 16]) |
Series 객체에 .reset_index()를 사용하는 경우 기존 인덱스가 첫 번째 변수, 기존 값이 두 번째 변수인 데이터프레임이 생성된다. 단, drop 인자에 기본값 False가 아닌 True로 할당할 경우 그대로 Series를 유지한다.
1 | ser.reset_index(drop = True) |
DataFrame 객체는 row와 column 부분이 다 인덱스이다. .index는 row 인덱스를, .column은 column 인덱스인 변수명을 추출한다.
1 | df = pd.DataFrame({"type": ["A", "A", "B", "B"], |
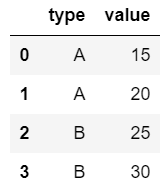
1 | df.index |
- .loc: 인덱스, 논리값, 텍스트 기반 데이터프레임 인덱싱
- .iloc: 정수 기반 데이터프레임 인덱싱
※ .loc, .iloc 인덱서의 경우 콤마(,) 앞은 row, 뒤는 column 지정
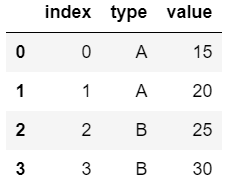
.reset_index()는 Series 객체에서 사용했던 것과 마찬가지로 기존 인덱스를 첫 번째 변수명으로 가져다준다. 이 성질을 활용하여 .groupby() 등 추가로 추가로 다단(multi level) 인덱스의 경우 flat 하게 만들어주어 다단 인덱싱을 가지는 DataFrame 핸들링이 생소한 경우 유용하게 사용할 수 있다.
1 | df.reset_index() |
.set_index()는 인덱스 기반 연산에 특화된 메서드인 .xs() 사용. .join()으로 데이터 병합. 또는 시계열 분해에서 주로 활용된다.
1 | df.set_index("type") |

변수명 변경
.rename() 메서드를 사용한다. 단, inplace 인자에 True를 사용하는 것은 일반적인 Python 코드 작성 방식과 달라지기 때문에 피하도록 한다.
1 | df = pd.DataFrame({"type": ["A", "A", "B", "B"], |
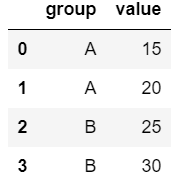
다음과 같이 딕셔너리를 활용하며, key에는 기존 변수명을 명시하고 value에는 신규 변수명을 명시한다. 두 개 이상의 변수명을 한 번에 바꿀 수도 있다.
1 | df.rename(columns = {"type": "group"}) |
df.columns에 바로 값을 할당해도 되긴 하나, 변수명 전체를 입력하지 않으면 안되기 때문에 언듯 간결해보이나 실무에서는 잘 쓰이지 않는 코드이다.
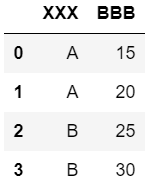
1 | df.columns = ["XXX", "BBB"] |
속성 변환
.astype()을 활용한다. int는 정수, str은 문자를 뜻한다.
1 | df["value"].astype("str") |
요약하기
- .value_counts(): 특정 변수의 원소 개수를 세어준다. normalize인자에 True를 입력하면 각 원소별 비율을 반환한다.
- .groupby(): 특정 변수를 기준으로 묶어서 연산한다. 2개 이상의 변수 선언시 리스트로 묶어준다. 뒤에는 Series 기본 메서드나 .agg()를 붙여 연산한다.
- .where(): 특정 조건이 아닌 것은 결측값으로 만든다. 가끔 np.where() 대신 사용을 하기도 하는데 딱히 사용을 권장하지 않는다.
- pd.crosstab(): 두 변수의 원소간 조합 빈도 확인. .value_counts()와 같이 normalize 인자를 사용하여 다양한 비율을 계산할 수 있다.
1 | pd.crosstab(df["type"], df["value"]) |

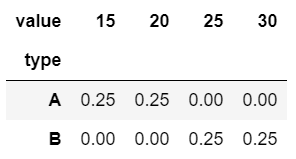
1 | pd.crosstab(df["type"], df["value"], normalize = True) # 전체 중 특정 원소의 비율 |
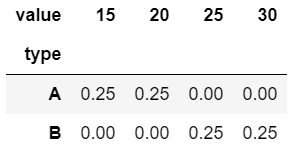
1 | pd.crosstab(df["type"], df["value"], normalize = 0) # row 방향 |
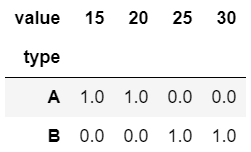
1 | pd.crosstab(df["type"], df["value"], normalize = 1) # column 방향 |
- pd.cut(): 불규칙한 구간을 보다 손쉽게 나누기 위해서 사용하는 함수. right 인자는 False로 사용하는 경우가 많다.
1 | df = pd.DataFrame({"age": [5, 20, 29, 33, 41], |
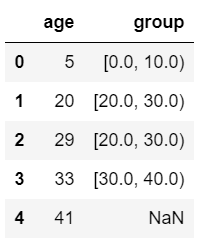
위 결과를 보면 5는 0이상 10미만, 20은 20이상 30미만 구간으로 group 변수에 표기된 것을 알 수 있다.
피벗
- .melt(): wide form 데이터를 long form 데이터로 변환. 주로 통계처리 직전이나 그래프 그리기 직전의 데이터 모양을 만들 때 사용한다.
- .pivot_table(): long form 데이터를 wide form 데이터로 변환. 데이터를 요약할 수 있으며 주로 군집분석(clustering analysis) 직전의 데이터 모양을 만들 때 사용한다.
- .transpose(): 행렬을 전치시키는 것과 같은 동작을 한다. 활용도는 낮으나 가끔 임시 방편으로 활용하기도 한다.
시간 처리
시간 데이터가 아닌 것을 시간 속성으로 만드는 것이 중요하다. 변환 전의 문자가 표준형식이 아닐 경우 pd.to_datetime() 함수의 format 인자를 활용하면 된다. 시간 요소에 대응되는 특수문자는 해당 함수의 공식문서와 format 인자의 문서를 확인하도록 하자.
1 | ser_t_01 = pd.Series(["2077-01-01", "2077-12-28"]) |
텍스트를 시간 데이터로 변환한 이후에는 .dt를 활용하여 각종 시간정보를 꺼낼 수 있다.
1 | ser_t_01.dt.year |
시계열
- .rolling().mean(): 단순 이동 평균
※ ser.rolling(window = 5).mean(): 5단위 시간 이동평균
- .ewm().mean(): 지수 가중 이동 평균(EWMA)
※ ser.ewm(alpha = 0.5).mean()
기타(정리 대기)
- .concat(): 두 개 이상의 데이터프레임을 합침
※ axis 사용에 주의. 인덱스 문제 발생 가능
- .merge(): 두 데이터프레임 병합(join)
※ df1.merge(df2, left_on = “col1”, right_on = “col2”, how = “left”)
※ how: “left”, “right”, “inner”, “outer”
- .drop(): 특정 변수 제거 가능
- .dropna(): 결측치가 있는 row 제거 가능
※ how: “any”, “all”
- .fillna(): 결측치를 특정 값으로 치환(Series에도 사용 가능)
- .sort_values(): 지정 변수 기준 데이터프레임 정렬(오름차순, 내림차순)
- .sample(): 특정 row를 단순 임의 추출
※ n: 정수로 입력하며 row개수 지정, frac: 비율로 입력(0~1)
- pd.get_dummies(): 가변수 생성. 필요시 drop_first = True로 첫 가변수 제거 가능
- .str.replace(): 텍스트 치환
<실기시험 대비 시리즈 - Python>
Python 실기시험 대비 정리 노트 - 00
Python 실기시험 대비 정리 노트 - 01
Python 실기시험 대비 정리 노트 - 02
Python 실기시험 대비 정리 노트 - 03
Python 실기시험 대비 정리 노트 - 04

