브라이틱스(Brightics)에서 무작위 row를 추출하여 데이터를 두 개로 나눌때 사용하는 Split Data 을 알아본다.
Split Data
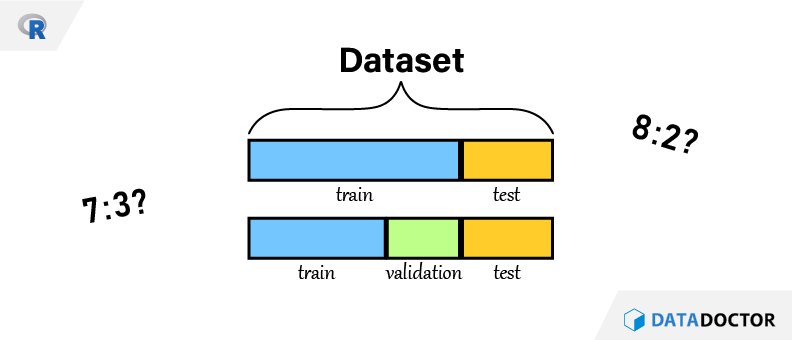
머신러닝을 모델링을 할 때 데이터 전처리가 끝난 이후 꼭 하는 것이 있다. 바로 학습(train) 데이터세트와 평가(test) 데이터세트 분리이다. 7:3인지? 8:2인지? 그리고 validation set은 또 무엇인지 알아보도록 하자.
Data Doctor
Diagnose and Treat via Data.
Seoul, Korea
포스트
304
카테고리
57
태그
675
Python / Crawling
Python / GIS
Python / Etc
Update your browser to view this website correctly. Update my browser now
×