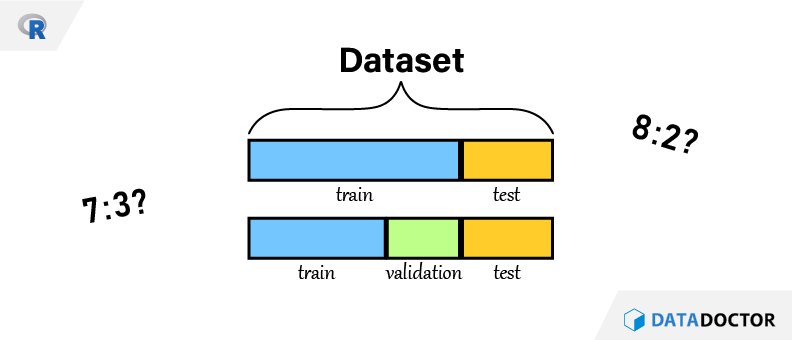
머신러닝을 모델링을 할 때 데이터 전처리가 끝난 이후 꼭 하는 것이 있다. 바로 학습(train) 데이터세트와 평가(test) 데이터세트 분리이다. 7:3인지? 8:2인지? 그리고 validation set은 또 무엇인지 알아보도록 하자.
데이터세트 준비
ggplot2 패키지의 diamonds 데이터로 실습하도록 하겠다.
1 | library("ggplot2") |
기본 함수 사용
sample() 함수를 사용해보겠다. 정확하게 몇 개를 나눈다면 sample() 함수의 size 인자를 사용하면 된다.
1 | set.seed(123) |
그럼 학습 데이터세트는 만들었으니 평가 데이터세트를 추출해보자. 숫자가 작으면 손으로라도 하겠지만 당장 학습 데이터세트를 추출하기 위한 색인(index)숫자가 4만개라 여의치 않다.
그럼 집합으로 접근하는 것은 어떨까? 어차피 전체 집합에서 학습 데이터세트의 색인을 추출했기 때문에 이의 여집합을 보면 될 것이다. R 기본함수 중 집합관련 함수 setdiff() 함수를 사용하면 다음과 같다.
1 | setdiff(x = 1:5, y = c(1, 2, 4)) |
전체 집합에 해당하는 원소를 인자 x에 할당하고, 학습 데이터세트의 색인숫자를 인자 y에 할당하면 앞에서 말한 여집합에 해당하는 원소를 얻을 수 있다.
1 | df_test = df[setdiff(x = 1:nrow(df), y = idx_train), ] |
하지만 R에는 마이너스 부호를 활용하여 setdiff() 함수와 거의 비슷한 기능을 구현할 수 있다.
1 | df_test = df[-idx_train, ] |
다음은 사전에 지정한 정수가 아니라 비율 계산으로 데이터세트를 분리하여 70%의 학습 데이터세트를 분리하는 코드는 다음과 같다.
1 | set.seed(123) |
실제로 사용하는 코드는 더 간단하겠지만 일부러 코드를 좀 더 풀어보면 앞의 코드와 같다. 비율에 해당하는 값을 proportion 객체에 할당하면 되겠고, round() 함수가 기본을 반올림 하여 1의 자리까지 산출해주기 때문에 앞의 코드와 같이 사용하였다. 물론 round() 함수 이외에도 floor() 같은 수를 어림하는 함수를 사용해도 괜찮다.
패키지 사용
dplyr
dplyr 패키지는 앞에서 구현해본 표본추출을 보다 간단하게 할 수 있게 지원하는 함수가 있다. sample_n() 함수는 지정한 개수만큼, sample_frac() 함수는 지정한 비율만큼 추출해주며 sample_frac() 함수를 사용한 예제는 다음과 같다.
1 | library("dplyr") |
dplyr 패키지를 통한 샘플링의 경우 숙지해야 할 사항이 있다. 보통 표본 추출은 확률적 표본 추출을 하기 때문에 임의의 행(random row)를 추출하지만 예전 버전(2021년 이전)의 dplyr 의 함수는 지정된 숫자 또는 비율 만큼 첫 행 부터 뽑아온다. 그렇기에 별도의 목적이 있지 않은 이상 표본이 편향될 가능성이 확률적 표본 추출 보다 높기 때문에 조심하도록 하자. 혹시 불안하다면 install.packages() 함수로 dplyr 패키지를 업데이트 한 다음에 사용하는 것도 방법이다.
caTools
머신러닝 패키지 중 하나인 caTools의 예제는 다음과 같다.
1 | library("caTools") |
최적의 비율
그런거 없다. 학습:평가 비율을 7:3으로 하거나 8:2로 하는 것을 영어권에서는 rule of thumbs 로 친다. 즉, 저렇게 하면 따봉 하나 준다는 얘기이다. 명확한 기준은 아닐지언정 적당히 저정도 하면 끄덕끄덕 하면서 넘어가는 숫자이다. 혹시나 연도로 구분되어 있는 경우에는 5개년도 데이터가 있다면, 최초 4년은 학습으로 사용하고 마지막 1년치 데이터를 평가로 사용하기도 한다.
하지만 표본추출은 확률적 표본추출 중에서 단순 임의 추출을 사용한다고 했을 때, 독립변수의 이상치만 잔뜩 뽑혀서 test 세트에 들어간다던지 명목형 변수의 특정 class만 한 변수에 쏠릴 수 있다. 이 문제를 해결하려면 군집 또는 층화 표본추출을 사용해야 한다. 표본추출 관련해서 좀 더 전문적으로 하고싶다면 표본조사론 또는 sampling 패키지를 참고하도록 하자.

